
Handbok
Vill du lära dig att använda språkteknologi i din forskning? I Swe-Clarins handbok finns systematiska instruktioner och belysande exempel på hur man besvarar olika forskningsfrågor med våra verktyg och material. En bärande tanke är att våra verktyg ska gå att tillämpa på användarens egna texter, en annan att användaren själv avgör om hen vill jobba med verktygen via webbklient eller ladda hem dem till sin egen dator.
Exempeltexterna i handboken finns förutom i de enskilda verktygen även publikt tillgängliga i Språkbanken Texts Korp, och kommer framöver att användas i flera användningsfall. På det viset kan den som är nybörjare på området få en chans att stegvis fördjupa sig och komma tillbaka till samma källor gång på gång. Textresurser publiceras med öppna licenser och källkod finns fritt nedladdningsbar i öppna repositorier.
1. Namn eller namnliknande entiteter
1.1 Exempel: Statens offentliga utredningar
2. Ordbild – Ordens bästa vänner
2.1 Exempel: Nordiska museets frågelistor
3.1 Exempel: Nordiska museets frågelistor
5. Temamodellering (topic modeling)
9. Attitydanalys (sentiment analysis)
Introduktion
Språkteknologin har sedan lång tid utarbetat verktyg och metoder för att på olika sätt beforska språkets form. Inom Swe-Clarin är vi övertygade om att dessa verktyg och metoder också skulle kunna vara till nytta och glädje för den forskning som mer intresserar sig för språkets innehåll. Med denna handbok vill vi erbjuda en introduktion till nya arbetssätt för forskare inom framför allt humaniora och samhällsvetenskap. Vi hoppas därmed kunna bidra till ny kunskap och vidgade perspektiv på samhällets historia och utveckling.
Clarin (Common Language Resources and Technology Infrastructure) drivs i Sverige av ett konsortium under ledning av Språkbanken vid Göteborgs universitet. Arbetet finansieras av Vetenskapsrådet och i konsortiet ingår Institutet för språk och folkminnen, Riksarkivet, Svensk Nationell Datatjänst samt språkteknologiska centra vid KTH och universiteten i Lund, Linköping, Uppsala och Stockholm. Motsvarande infrastrukturer finns i arton andra europeiska länder och de är alla sammankopplade i CLARIN ERIC (European Research Infrastructure Consortium).
Swe-Clarins uppgift är att etablera en nationell infrastruktur för språkteknologi som skapar förutsättningar för tvärvetenskapligt arbete och breda forskningsansatser inom humaniora och samhällsvetenskap. Syftet är att göra språkresurser (texter, lexikala resurser, annoterade ljud- och videoinspelningar, ontologier etcetera) och databaserade språkverktyg (informationsextrahering, taligenkänning och text mining system etcetera) mer tillgängliga och lättanvända för forskare inom alla ämnen, men i synnerhet inom det humanistiska och samhällsvetenskapliga området.
Språkteknologin ger en forskare möjlighet att arbeta med vedertagna metoder, men i betydligt högre tempo. Kanske viktigare är att den också öppnar för essentiellt nya forskningsfrågor och till exempel möjliggör bearbetning av väldiga datamängder som tidigare varit omöjliga att hantera.
Språkteknologin kan dock inte lösa allt. Till vad som kan betecknas som svagheter hör bland annat beroendet av textkällor i digital och maskinläsbar form. Inom många domäner finns fortfarande för lite material för forskningen att arbeta med, och alltför ofta saknas de öppna licenser som är en förutsättning för automatiserad bearbetning (data mining). Språkteknologin kräver alltså av oss att vi gör mer material fritt och öppet tillgängligt för bearbetning, att vi digitaliserar mer (äldre) text och att vi skapar så effektiva arbetsflöden som möjligt. Det innebär bland annat ett öppet förhållningssätt till kollaborativa forskningsprocesser där annoteringar och annan berikning av källtexter delas med andra forskare, som därmed kan bygga vidare på redan nedlagt arbete.
1. Namn eller namnliknande entiteter
Du vill hitta eller gruppera träffar utifrån namn på personer, organisationer och platser i en längre text eller samling av texter (korpus). Du behöver automatisk uppmärkning av namnliknande entiteter.
Med namnliknande entiteter avses här personnamn som Elisabeth Persdotter och Mickel Thomasson Koljock, organisationer som Kammarkollegiet och Ovikens socken, eller geografiska platser som Luleå och Imandra-sjön. Sådana entiteter är ofta värdefulla nycklar för den som vill förstå källtexter, värdera och sätta dem i relation till varandra, eller spåra vissa företeelser genom tid och rum. Automatisk uppmärkning kan hjälpa dig att hitta dem snabbare och enklare.
1.1 Exempel: Statens offentliga utredningar
Kungliga biblioteket har digitaliserat statens offentliga utredningar (SOU) 1922-1999, cirka 5 600 volymer. SOU:er publicerade efter 1999 finns på Regeringens hemsida. I Kungliga bibliotekets material finns utredningar om allt från smalspårig järnväg och diabetes till skolmåltider och migration. Utredningarna skrivs av utredningskommittéer eller ensamutredare på direkt uppdrag av regeringen, och ligger ofta till grund för nya lagar eller andra politiska beslut. De kännetecknas i allmänhet av formellt språk, torr stil, hög frekvens av faktauppgifter och många referenser till andra källor.
Lappskatten
Vårt exempel, Om lappskattelandsinstitutet och dess historiska utveckling (SOU 1922:10) av Åke Holmbäck, tecknar på knappt hundra sidor den historiska bakgrunden till den då gällande modellen för beskattning av den samiska befolkningen i norra Sverige. Texten är en renodlad kunskapsöversikt utan explicita förslag, men den bör ha legat till grund för riksdagens beslut att avskaffa den så kallade lappskatten 1928.
Utredningen inleds med ett förord ställt till konungen, och en lista över förkortningar. Därefter följer en kronologisk framställning av utvecklingen på området. Den är indelad i sex kapitel (I-VI) från de äldsta handlingarna till den nuvarande indelningen. Utredningen avslutas med tjugo bilagor, i huvudsak äldre domslut och andra avgöranden i ärenden om lappskatt från perioden 1655–1897.
1.2 Fördjupning
Du kan naturligtvis göra enkla fritextsökningar i en text om du redan vet vad du letar efter, och nöjer dig med träff på exakta textuttryck. Här kanske till exempel lappfogden Olof Burman eller Könkämä lappby (sameby).
Prova att filtrera (gruppera) en nyckelordssökning, och hitta till exempel alla instanser av Burman genom att skriva in ordformen Burman i Korp och klicka på enter. Dina träffar kommer upp i en KWiC-lista som visar alla ställen där Burman förekommer:
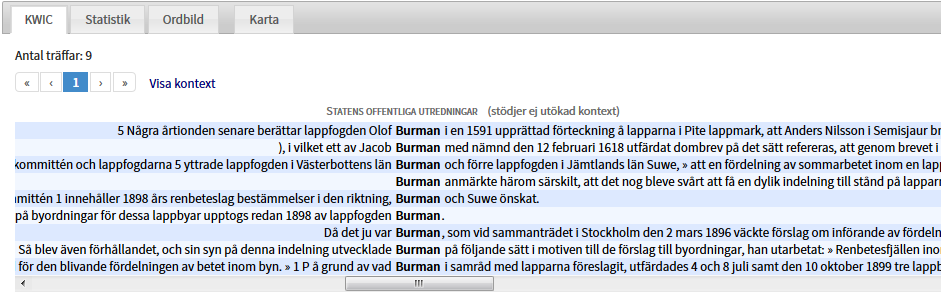
Du kan på samma sätt skriva in flera ord i sökfältet, till exempel Olof Burman, och få träff på alla ställen där Burman följer direkt på Olof. Men den allra enklaste typen av sökningar hittar bara det som stämmer exakt med sökuttrycket.
1.3 Öva/Pröva
Ett första steg för att få svar på andra frågor kan vara att använda sig av namnliknande entiteter. Det betyder att man tillför information och skapar en statistisk modell som kan filtrera fram smartare träffbilder. Det gör man genom att märka upp ett antal instanser av den typ av entitet man är ute efter (till exempel personer, organisationer eller platser), och generera en modell för automatisk uppmärkning av hela texten. Uppmärkningen kan göras manuellt eller baseras på färdiga ordlistor och ordklassmärkningar.
Prova i första hand att använda en redan befintlig modell för uppmärkning av namnliknande entiteter, som till exempel den som finns i Sparv eller i vår 240-modell. En sådan modell gör det möjligt att navigera i texten genom att gruppera allt som uppfyller vissa kriterier för uppmärkning, till exempel att referera till personer, organisationer eller platser. I så fall väljer du önskad kategori i rullgardinsmenyn, som här förvalt platsnamn i Korp
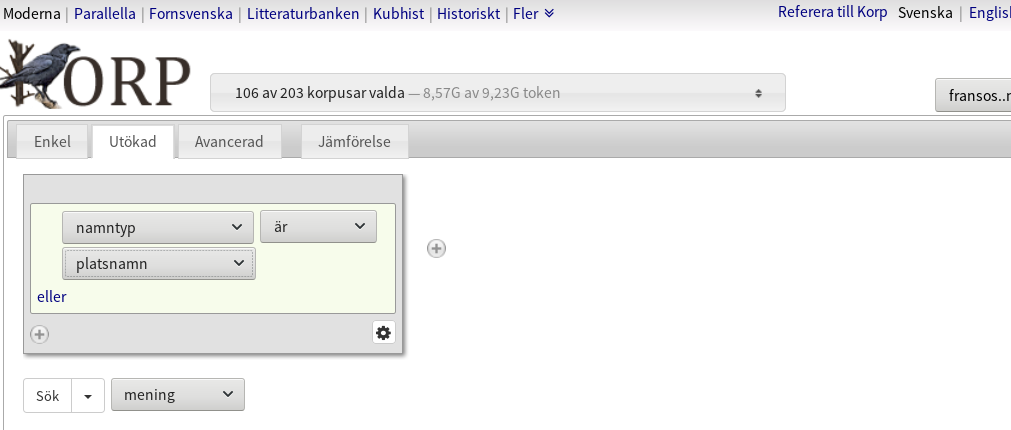
Dina träffar kommer upp en och en i den ordning de uppträder i texten, och du kan klicka dig framåt och bakåt mellan instanserna. Du kan även kombinera filtrering och navigering enligt ovan. Samma arbetssätt gäller om du vill söka efter andra typer av entiteter, som till exempel yrken, tidsuttryck eller ekonomiska värden (se vidare användningsfall 3 Händelse).
Genom uppmärkning blir det möjligt att hitta svar på frågor som:
- Vilka personer blir hörda i utredningen?
- Vilka samebyar lyfts fram som exempel?
1.4 Gör-det-själv
Ger den befintliga modellen för namnuppmärkning inte tillräckligt goda resultat kan det vara värt att göra en ny. På det viset får du en uppmärkningsmodell som är skräddarsydd efter din uppgift och de texter du arbetar med. Fungerar den väl kan den även användas på andra texter av samma typ. För att träna en enkel modell behöver du lägga några timmar på att göra uppmärkningen, men sedan går det på sekunder att köra modellen på större textmängder så det finns mycket tid att vinna i jämförelse med andra arbetssätt.
Märk upp
Börja uppmärkningen med att välja ett kortare avsnitt från någon av dina texter, kanske 5-10 sidor A4. Ta ett avsnitt som är representativt för dina texter, och som innehåller en någorlunda balanserad mängd av de kategorier du vill märka upp. Klipp ut och spara det som en separat fil i ordbehandlingsformat. För att få avsnittet omvandlat till kalkylbladsformat laddar du upp det på Swe-Clarins segmenteringstjänst för ordbehandlingsdokument
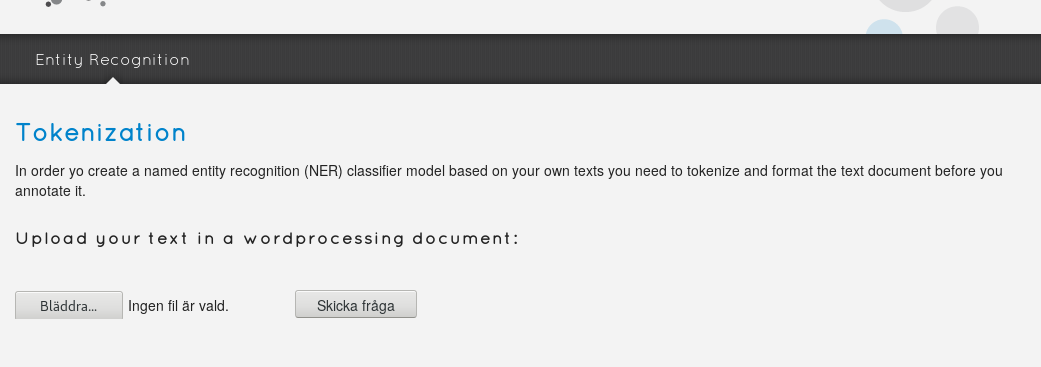
Du får tillbaka avsnittet i kalkylbladsformat med två kolumner. Du ska se hela textflödet i kolumn ett, i rätt ordning men segmenterat med ett ord eller en token på varje rad. Hela kolumn två är till en början märkt med O (other). Det är där du ska arbeta med dina klassificeringar.
Så här kan det se ut:
| Tomas |
O |
| Nilsson |
O |
| beviljades |
O |
| Alawuoma |
O |
| vid |
O |
| Rounala |
O |
| kyrka |
O |
Gå igenom kolumn ett och markera alla ord som representerar namn på personer, organisationer eller platser genom att skriva över O i kolumn två med en bokstavskod: PERS för personer, ORG för organisationer respektive LOC för platser (locations). För ord som inte representerar personer, organisationer eller platser låter du O stå kvar. Då kan det bli så här:
| Tomas |
PERS |
| Nilsson |
PERS |
| beviljades |
O |
| Alawuoma |
LOC |
| vid |
O |
| Rounala |
LOC |
| kyrka |
O |
Varje ord kan inte ges mer än en uppmärkning. I vårt text-exempel måste du till exempel själv bestämma dig för om Jokkmokks socken ska märkas som organisation (ORG/ORG) eller plats (LOC/O). Argument kan finnas för båda alternativen, men det viktigaste är att uppmärkningen är konsekvent inom sig och till exempel märker alla socknar på samma sätt. Viktigt är också att du märker samtliga relevanta entiteter i ditt avsnitt. Skulle du missa på några ställen ger det väsentligt sämre underlag för att generera din modell.
Tänk också på att kontrollera dina egna märkningar, så att du inte skrivit fel eller tappat någon bokstav. Gör så här: Välj i kalkylbladets meny alternativet Data, Filtrera, Avancerat och tryck ok. Då markeras troligen flera kolumner, välj rätt kolumn (B) i fältet listområde och fyll i till sista raden. Bocka i ”enbart unika poster” och tryck ok. Då visas första förekomst för varje unikt värde. Skulle det finnas flera olika värden än de du valt att markera med (till exempel PERS, ORG, LOC), så får du ändra felaktig märkning och upprepa processen tills endast de värden syns som du vill ha med.
Företeelser som i kalkylbladet splittras på flera rader märks lika på varje rad, till exempel förlaget Almqvist & Wiksell (ORG/ORG/ORG). För personer märks även eventuella titlar, så här:
| professorn |
PERS |
| vid |
O |
| Uppsala |
ORG |
| universitet |
ORG |
| d:r |
PERS |
| K. |
PERS |
| B. |
PERS |
| Wiklund |
PERS |
Du behöver minst 200 uppmärkta instanser, men ju fler du gör desto bättre kvalitet kan det bli på utfallet. Skulle det visa sig att ditt textavsnitt inte räcker till 200 uppmärkningar får du göra om proceduren såhär: Spara din redan gjorda märkning i kalkylbladsformat på skrivbordet, välj ett nytt lite längre avsnitt med samma början som det ursprungliga, ladda upp det och kopiera sedan av din märkning och klistra in i det nya kalkylbladet. Fyll på med nya uppmärkningar till (minst) 200.
När du är klar med uppmärkningen laddar du upp din fil till Swe-Clarins modellträningstjänst för kalkylblad som kör träningsprogrammet på den uppmärkta texten för att generera en ny modell. Ta vara på din uppmärkningsfil, den är en värdefull resurs för bland annat återsökning och validering och kan också komma till nytta i fortsatt arbete med ytterligare märkning av samma eller andra texter.
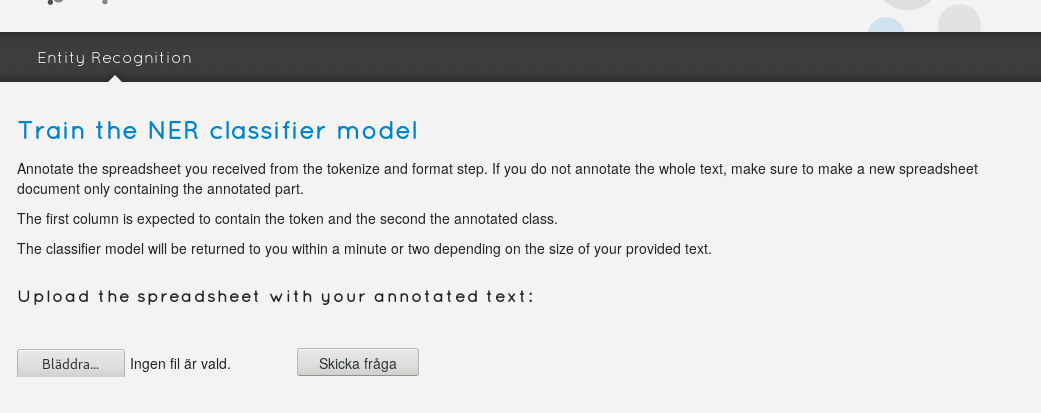
Nu är det dags att låta den nya modellen automatiskt märka upp hela din källtext, som du laddar upp (i ordbehandlingsformat, max 80 MB) på Swe-Clarins entitetsuppmärkningstjänst för ordbehandlingsdokument.
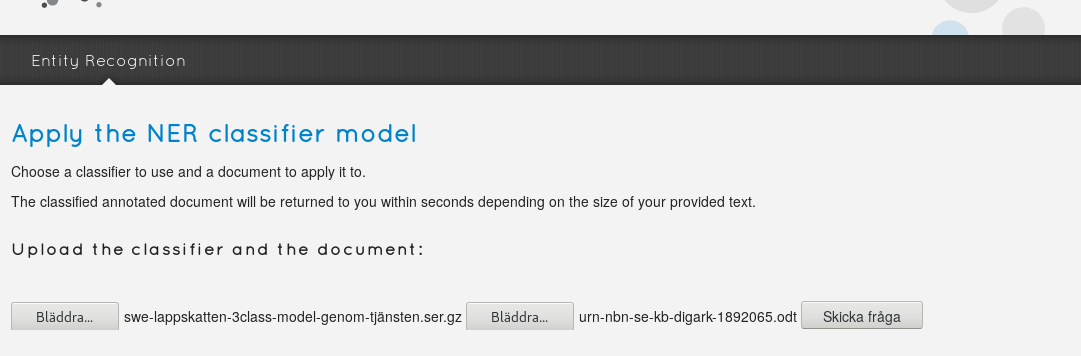
Du får tillbaka den automatiskt uppmärkta texten i kalkylbladsformat, och andra kolumnen innehåller nu automatisk uppmärkning efter din egen annoteringsmodell. Ett utsnitt ur exempeltexten, med vår 240-modell applicerad, visar till exempel följande uppmärkning av instanser som modellen uppfattat som personer.
Landshöfdinge-Embetet har tagit detta ärende i öfvervägande; Och alldenstund Kristina Josefina Larsdotter medelst behörigt prestbevis styrkt sig vara äldsta dottern till förbemälde Lars Jonsson, hvilken icke efterlemnat någon son och som genom Landshöfdinge-Embetets utslag den 31 December 1847 erhållit införsel uti ifrågavarande lappskatteland, alltså och då såväl Larsdotter som hennes man Lars Thomasson Laula enligt förenämnda prestbevis åtnjuta medborgerligt förtroende, pröfvar Landshöfdinge-Embetet skäligt bevilja sökandena Kristina Josefina Larsdotter och hennes man bemälde Lars Thomasson Laula…
Den har, som du ser, träffat rätt på fem av sex personnamn (ej Larsdotter), men å andra sidan misstolkat alldenstund (som titel?) och missat att Landshöfdinge-Embetet är en organisation. Du kan utforska texten ytterligare genom att orientera mellan de märkta entiteterna. Eventuellt kan du också göra kompletterande uppmärkningar för att ge modellen bättre underlag, eller arbeta med andra teman för uppmärkning, se vidare användningsfall 3 Händelse.
1.5 Hur bra kan det bli?
Vad som kan betraktas som tillräckligt bra beror bland annat på hur texterna du arbetar med ser ut från början och vad du vill använda resultaten till. Det går kanske inte att få helt perfekta resultat, men de kan alltid bli bättre. Det går till exempel fint att stegvis förbättra modellerna, genom att märka upp fler entiteter, tills de ger ett utfall man är nöjd med.
Träffsäkerheten i en modell mäts efter hur en sökning fångar dels hög frekvens av relevanta entiteter (precision), dels låg frekvens av irrelevanta entiteter (recall). Navigerar man sig igenom de uppmärkta orden efter en person vill man kanske hitta alla instanser av namnet, och få med så lite annat som möjligt. Men när en modell appliceras på en text kan det ändå hända att den å ena sidan missar ord som du velat få träff på, å andra sidan ger träffar som inte stämmer med vad du ville hitta. Att det blir så kan bero på flera olika saker, och hur du hanterar det styrs av dina egna behov och forskningsfrågor.
- Språkbruk förändras över tid och vissa företeelser beskrivs med helt andra ord idag än till exempel 1922. Tydligast i vår exempeltext är att en sökning på ordet same ger noll (0) träffar och en på ordet lapp hundratals. För att hitta något meningsfullt behöver man alltså anpassa sig till den aktuella tidens terminologi. Detsamma kan gälla för sakområdet specifik terminologi. De historiska skatter utredningen handlar om innefattar många olika poster – bland andra tionde, haxepalka och lagmansränta – som man inte hittar på sökuttrycket skatt.
- Flerspråkighet kan vara en utmaning för automatiserad bearbetning då den ger större variation i bland annat stavning. I vårt exempel finns referenser till finska och ryska källor som Kolttain mailta av Paulaharju och Russkie lopari av Charuzin, men inga längre citeringar i löptexten. Texter med större språkvariation kräver fler uppmärkningar, som kan ge modellen bättre underlag för tolkning.
- OCR-läsningen kan ha blivit fel, vilket i sin tur kan bero på till exempel växlande lay-out och typsnitt, veck eller fläckar i det analoga originalet.
- Det finns också ord som stavas och uttalas likadant, men betyder olika saker (homonymer). En sökning på ordet timmer i vårt exempel ger till exempel fyra träffar. Men den som letar efter grova trädstammar som ska sågas till bräder hittar något helt annat, då timmer i den här texten är ett räknemått för skinn av småvilt.
2. Ordbild – Ordens bästa vänner
Du vill veta mer om sammanhanget kring de begrepp som intresserar dig. Du behöver titta på ordbilder i den text eller samling av texter (korpus) du arbetar med för att se vilka ord som frekvent finns i anslutning till det du söker.
Ordbilder är ett språkverktyg som kan hjälpa dig att hitta fram till intressanta ställen i texten, och dessutom ge dig uppslag till vidare sökningar. För att kunna skapa ordbilder måste du utgå ifrån en text med uppmärkta satsdelar, i det här fallet en dependensparsad källtext.
2.1 Exempel: Nordiska museets frågelistor
Nordiska museet har digitaliserat avskrifter av, från början handskrivna, svar på de frågelistor som sedan 1920-talet varit en viktig del av museets dokumentationsarbete. Merparten av material från perioden 1928-1950 finns tillgängligt via Korp, ca 250 olika listor med närmare 30 000 svar. Att ett hundratal listor (med knappt 9 000 svar) från perioden saknas i det digitaliserade materialet beror på att dessa inte prioriterades för transkribering på 1980-talet och därför inte heller genomgått skanning 2015. Fullständiga förteckningar över samtliga frågelistor finns hos Nordiska museet.
Listorna handlar om allt från långdans till sorgkläder, knuttimring och spökhistorier. Svar finns från hela landet. Många av dem är skrivna av så kallade fasta meddelare, intresserade personer som antogs ha god förankring på sin hemort och som i sin tur samlade upplysningar från andra (gärna äldre) så kallade sagesmän i trakten. Texterna är ofta talspråkligt och dialektalt präglade. Varken meddelarstaben eller svaren är statistiskt representativa för landet, men de ger ändå värdefulla inblickar i kulturhistorien som den kunde te sig från gräsrotsnivå.
Marknadsnöjen
Vårt exempel, frågelistan Marknadsnöjen och kringförda sevärdheter (Nm 122), formulerades 1944 av Mats Rehnberg och Arvid Stålhane och gav till sist 102 svar. Alla kom dock inte in direkt, utan texter finns från en följd av år fram till början på 1960-talet, och några senare ändå. De beskriver ofta minnen från äldre tid och ger alltså inte en bild av efterkrigstidens Sverige.
I sammanställningen ligger själva frågeschemat först och där framgår att museet söker uppgifter om många specifika marknadsnöjen – ormtjusare, kasperteater, vaxkabinett – men av någon anledning inte regelrätta cirkusar. Efter frågeschemat finns ett register över svaren, med geografiska uppgifter om meddelarna, och därefter ligger avskrifter av svaren i den ordning de kommit in till museet.
2.2 Fördjupning
Du kan naturligtvis göra enkla fritextsökningar i texten om du redan vet vad du letar efter, här kanske till exempel papegoja eller positiv. Men ordbilder kan ge dig mer meningsfulla svar på mer avancerade frågeställningar. När du skapar en ordbild ser du vilka ord (eller flerordsuttryck) som frekvent finns i anslutning till det du intresserar dig för. För ett verb visas till exempel vanliga subjekt och objekt i samma mening, för ett substantiv visas vanliga attribut, och vanliga verb som substantivet är subjekt eller objekt till. Våra verktyg gör det möjligt att söka svar på frågor som:
- Vilka konster var vanliga bland djuren som visades upp på marknader? Vad gjorde till exempel papegojorna?
En Korp-sökning på ordformen papegoja i vår exempeltext, tycks till exempel visa att papegojor på marknader ofta fanns i närheten av positiv, och mot betalning fick plocka fram lyckobrev till marknadsgästerna. Träffarna visas som KWiC-lista:
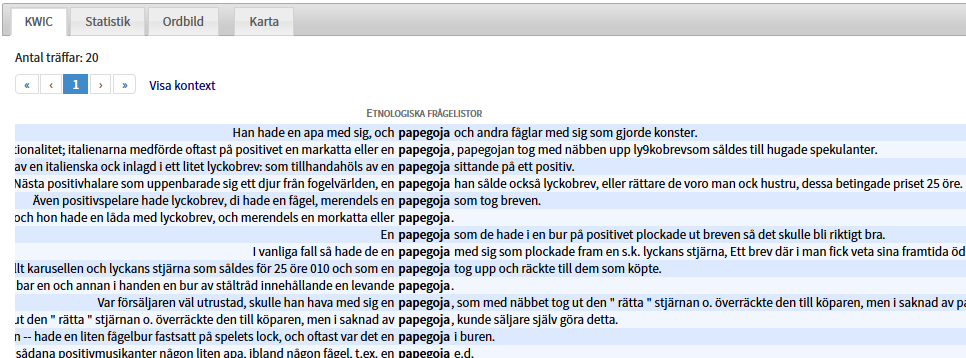
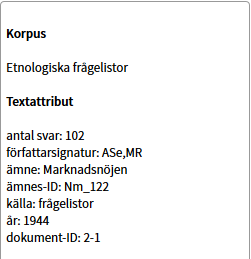
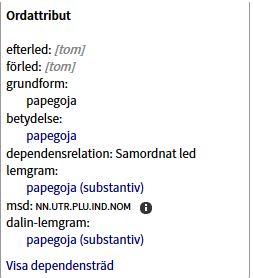
I rutan till höger på skärmen ser du information om vilken korpus texten kommer ifrån (Etnologiska frågelistor), vilken frågelista den aktuella sekvensen refererar till (ämne: Marknadsnöjen, ämnes-ID: Nm_122) med mera. Längre ned i samma ruta finns Ordattribut, med information om själva ordet papegoja (ordklass, lemgram, dependensrelation mm). Så här (klippt itu):
2.3 Öva/Pröva
Här vill vi presentera ett par olika termer och verktyg för sökning och presentation av sökresultat. Du kommer också att se hur resultaten påverkas av vilka modeller som används för uppmärkning och parsning.
Prova först att göra en lemgram-sökning. Ett lemgram är ett ordklassbaserat samlingsbegrepp för ett ords eller flerordsuttrycks samtliga böjningsformer. Lemgram gör det möjligt att i en och samma sökning hitta både papegoja, papegojan, papegojorna och så vidare. Det ger alltså träff på ett ords alla former, och kan förstås som ett sätt att hjälpa algoritmerna på traven genom att renodla sökning och reducera brus.
Erfarenheten visar att lemgram också ger tydligare resultat i din ordbild. Det kan du dra nytta av genom att i enkel Korp-sökning skriva in ett ord i sökfältet och invänta förslag. Skriver du papegoja föreslås endast papegoja (substantiv), men till exempel apa ger ett val på apa (substantiv), apa (adjektiv), och flerordsuttrycken apa efter (verb) och apa sig (verb). I utökad sökning väljer du lemgram i rullgardinsmenyn, skriver in ditt ord och inväntar på samma sätt förslag.

Till höger ser du en ruta med relaterade ord som dels kan visa dig om du är på rätt väg (du letar efter ett djur), dels leda dig vidare till andra sökningar. Du kan vidga sökningen ytterligare genom att göra den oberoende av versal och gemen, klicka bara i rutan för skiftlägesoberoende. Du kan också kryssa i om du vill ha med träffar med samma prefix (förled) eller suffix (efterled) som det du söker. För ett ord som papegoja får du då träff även på till exempel papegojbur. En sådan lemgram-sökning på papegoja (substantiv), ger i vårt exempel den här träffbilden:
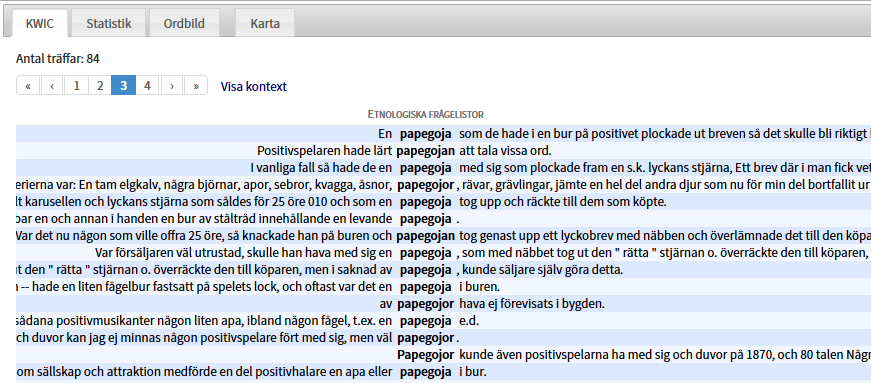
Prova att skapa en ordbild. Välj korpus i korpusväljaren (rullgardinsmenyn högst upp), här Etnologiska frågelistor. Gör en enkel sökning genom att skriva in ett ord, till exempel marknad, i textfältet. Du får upp en KWiC-lista som den här ovan. Klicka på Ordbild ovanför listan, så får du upp en bild som den här:
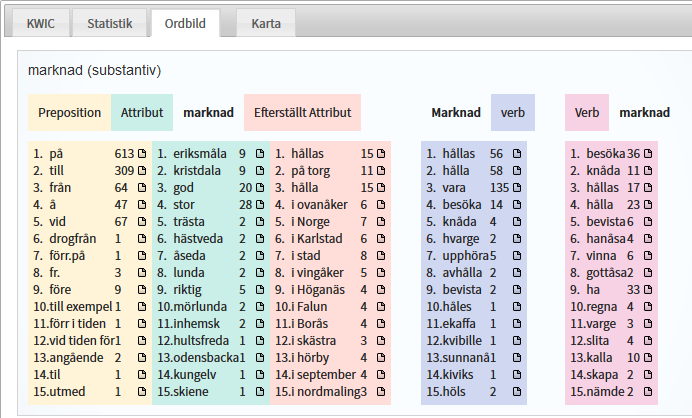
Du ser här den språkliga kontexten kring ett sökuttryck (här substantivet marknad), med de prepositioner, attribut och verb som mest frekvent finns i samma mening som sökuttrycket. Listorna i varje kategori visar aldrig mer än 15 träffar, och dessa är ordnade efter något som kallas Lexicographer's Mutual Information-värde.
I exemplet ovan ser vi till exempel många namn på orter där marknader hölls, vilket kan säga något om geografisk spridning av både marknader och uppgiftslämnare. Här finns tidsangivelser (i september, förr i tiden) och värderande attribut (god, stor, riktig), men man kan också se vad som verkar vara ett resultat av felaktig parsning (hvarge/varge är inte ett verb) eller misstolkning av tvetydiga ord (knåda refererar till Knåda i Ovanåker). Ordbilden kan också väcka nya innehållsliga frågor. Borde inte stora marknader som Jokkmokk och Kivik ha en mer framskjuten placering? Och hur kommer det sig att folk tycks ha gått till marknad så mycket oftare än från?
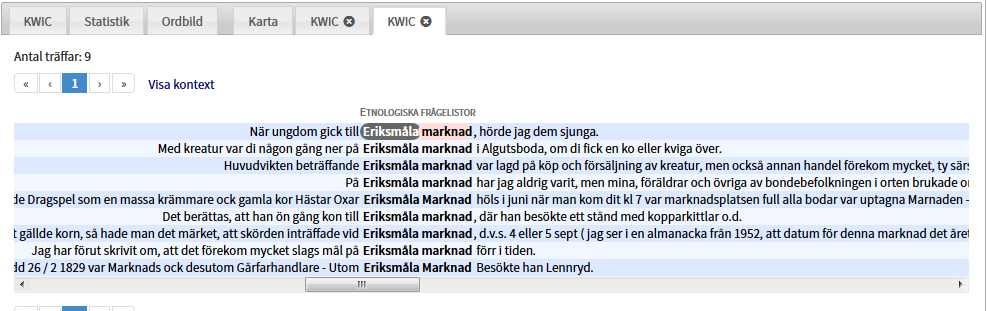
Intill varje ord finns en siffra som visar antal träffar, och en liten dokument-ikon. Om du klickar på den får du fram en ny KWiC-flik som listar de meningar där vald relation förekommer, så att du kan se det sammanhang som träffarna refererar till. Här till exempel Eriksmåla marknad:
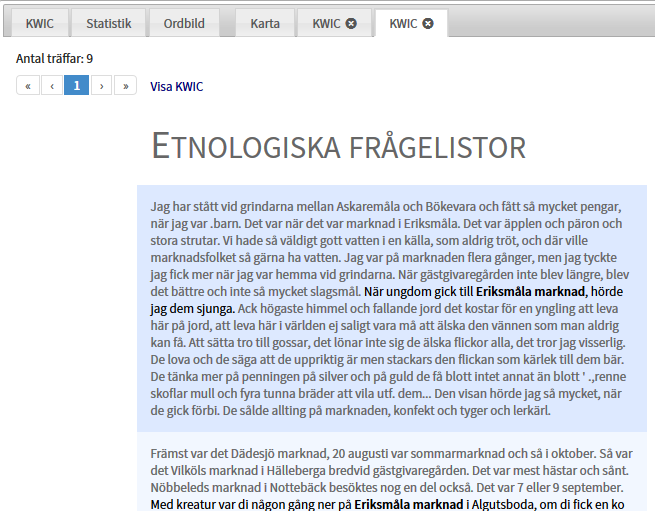
Du kan vidare klicka på Visa kontext, och får då upp hela det stycke som meningen står i, vilket ger ännu mer sammanhang till det sökta begreppet och den refererade meningen. Då kan det se ut såhär:
2.4 Gör-det-själv
Om du vill göra ordbilder för texter som inte finns i Korp måste du först förbereda dem genom att göra en uppmärkning av textens språkelement (ordklasser) och en dependensparsning som visar de olika satsdelarna och deras inbördes förhållanden enligt exemplet ovan.
2.5 Hur bra kan det bli?
Vad som kan betraktas som tillräckligt bra beror bland annat på hur texterna du arbetar med ser ut från början och vad du vill använda resultaten till. Vid varje överföring av text till en ny form finns en viss risk för informationsbortfall. Frågelistsvaren är till exempel från början handskrivna, och har transkriberats manuellt inom ett arbetsmarknadsprojekt på 1980-talet. De som då gjorde överföringen till maskinskrift kan till exempel ha läst fel i originalet, missuppfattat ord eller gjort rena skrivfel. Därför inleds varje transkriberad lista med en brasklapp om att man vid eventuell publicering av materialet bör kontrollera det mot originaluppteckningen.
Den OCR-lästa version av frågelistorna, som vi arbetar med här, utgår alltså från (möjligen inte helt korrekta) avskrifter. Dessutom är de ursprungliga frågelistsvaren skrivna av många olika personer, som alla satt sin prägel på texternas stil och utformning. Frågorna rör ofta traditionella eller ålderdomliga seder, och det är inte ovanligt att den som hållit i pennan sökt återge hur olika sagesmän formulerat sig. I materialen finns därför många vardagliga och dialektala uttryckssätt.
Dessutom ligger i den språkteknologiska metoden att precision i viss mån går förlorad då man arbetar med abstraktion som verktyg. Det finns helt regelbaserade modeller, men de vi talar om här bygger på manuell uppmärkning (annotering) och statistisk analys som generaliserar uppmärkningsmönster på större textmängder. Vad som är tillräckligt bra beror på syftet med analysen. För att minimera informationsförlust måste man hur som helst granska utfallet av olika modeller, jämföra hur det överensstämmer med originaltexten och kanske tillföra mer information (fler uppmärkningar).
3. Händelse
Du vill hitta en speciell typ av instanser som kan hjälpa dig att besvara dina forskningsfrågor om exempelvis ekonomiska transaktioner och värden. Du behöver göra en entitetsuppmärkning av för ditt syfte relevanta instanser.
En sådan uppmärkning gör det möjligt att överblicka vissa typer av händelser i potentiellt mycket omfattande källmaterial. Samma arbetssätt som det nedan beskrivna kan användas för andra typer av händelser (till exempel tvister, förflyttningar, sjukdomsfall) som kan bidra till att besvara dina frågeställningar.
3.1 Exempel: Nordiska museets frågelistor
Nordiska museet har digitaliserat avskrifter av, från början handskrivna, svar på de frågelistor som sedan 1920-talet varit en viktig del av museets dokumentationsarbete. Merparten av material från perioden 1928–1950 finns tillgängligt via Korp, ca 250 olika listor med närmare 30 000 svar. Att ett hundratal listor (med knappt 9 000 svar) från perioden saknas i det digitaliserade materialet beror på att dessa inte prioriterades för transkribering på 1980-talet och därför inte heller genomgått scanning 2015. Fullständiga förteckningar över samtliga frågelistor finns hos Nordiska museet.
Listorna handlar om allt från långdans till sorgkläder, knuttimring och spökhistorier. Svar finns från hela landet. Många av dem är skrivna av så kallade fasta meddelare, intresserade personer som antogs ha god förankring på sin hemort och som i sin tur samlade upplysningar från andra (gärna äldre) så kallade sagesmän i trakten. Texterna är ofta talspråkligt och dialektalt präglade. Varken meddelarstaben eller svaren är statistiskt representativa för landet, men de ger ändå värdefulla inblickar i kulturhistorien som den kunde te sig från gräsrotsnivå.
Marknadsnöjen
Vårt exempel, frågelistan Marknadsnöjen och kringförda sevärdheter (Nm 122), formulerades 1944 av Mats Rehnberg och Arvid Stålhane och gav till sist 102 svar. Alla kom dock inte in direkt, utan texter finns från en följd av år fram till början på 1960-talet, och några senare ändå. De beskriver ofta minnen från äldre tid och ger alltså inte en bild av efterkrigstidens Sverige.
I sammanställningen ligger själva frågeschemat först och där framgår att museet söker uppgifter om många specifika marknadsnöjen – ormtjusare, kasperteater, vaxkabinett – men av någon anledning inte regelrätta cirkusar. Efter frågeschemat finns ett register över svaren, med geografiska uppgifter om meddelarna, och därefter ligger avskrifter av svaren i den ordning de kommit in till museet.
3.2 Fördjupning
Man kan tänka sig att många människor gick till marknaden för att köpa eller sälja saker, och kanske skulle det vara möjligt att ur frågelistan om Marknadsnöjen få fram underlag om ekonomiska transaktioner. Om man söker efter något mycket distinkt i en text – till exempel ordet handpenning – kan man oftast hitta det utan vidare förberedelser. Vill man däremot få en överblick över till exempel alla typer av ekonomiska transaktioner, behöver man förbereda texten genom att göra en specialiserad manuell uppmärkning till stöd för en ny modell för automatisk uppmärkning. Genom att märka upp ord som refererar till ekonomi – till exempel pengar, priser, köp, försäljning – kan man skapa en modell som sedan kan användas för att automatiskt märka upp hela materialet enligt samma kriterier. Fungerar modellen väl kan man också använda den på andra källor av likartad karaktär.
3.3 Öva/Pröva
För den här typen av specialiserade frågeställningar är det inte så lätt att hitta redan befintliga uppmärkningsmodeller. Hittar du modeller som verkar applicerbara på dina material och frågeställningar bör de provköras och utvärderas både konceptuellt och utfallsmässigt. Kanske behöver du ändå skapa en egen modell.
3.4 Gör-det-själv
Börja uppmärkningen med att välja ett kortare avsnitt från någon av dina texter, kanske 5–10 sidor A4. Ta ett avsnitt som är representativt för dina texter, och som innehåller en någorlunda balanserad mängd av de kategorier du vill märka upp. Klipp ut och spara det som en separat fil i ordbehandlingsformat. För att få avsnittet omvandlat till kalkylbladsformat laddar du upp det på Swe-Clarins segmenteringstjänst för ordbehandlingsdokument .
Du får tillbaka avsnittet i kalkylbladsformat med två kolumner. Du ska se hela textflödet i kolumn ett, i rätt ordning men segmenterat med ett ord eller en token på varje rad. Hela kolumn två är till en början märkt med O (other). Det är där du ska arbeta med dina klassificeringar. Så här kan det se ut:
| tittskåp |
O |
| vars |
O |
| sevärdheter |
O |
| de |
O |
| utbjödo |
O |
| att |
O |
| få |
O |
| förevisa |
O |
| mot |
O |
| en |
O |
| billig |
O |
| slant |
O |
Gå igenom kolumn ett och markera alla ord som representerar ekonomi genom att skriva över O i kolumn två med en bokstavskod, som här EKON (ekonomi). För ord som inte representerar det du söker låter du O stå kvar. Då kan det bli så här:
| tittskåp |
O |
| vars |
O |
| sevärdheter |
O |
| de |
O |
| utbjödo |
EKON |
| att |
O |
| få |
O |
| förevisa |
O |
| mot |
O |
| en |
O |
| billig |
EKON |
| slant |
EKON |
Det är viktigt är att uppmärkningen är konsekvent inom sig och att den märker samtliga relevanta entiteter i avsnittet. Skulle du missa på några ställen ger det väsentligt sämre underlag för att generera din modell. Därför kan det vara klokt att tänka igenom dina kriterier ordentligt innan du börjar, så du inte tappar tråden under arbetet. Vill du till exempel räkna även de minsta summorna? Vill du ha med naturavärden i byteshandel, eller bildspråkliga talesätt som lön för mödan?
Tänk också på att kontrollera dina egna märkningar, så att du inte skrivit fel eller tappat någon bokstav i märkningen. Gör så här: Välj i kalkylbladets meny alternativet Data, Filtrera, Avancerat och tryck ok. Då markeras troligen flera kolumner, välj rätt kolumn (B) i fältet listområde och fyll i till sista raden. Bocka i ”enbart unika poster” och tryck ok. Då visas första förekomst för varje unikt värde. Skulle det finnas flera olika värden än de du valt att markera med (till exempel PERS, ORG, LOC), så får du ändra felaktig märkning och upprepa processen tills endast de värden syns som du vill ha med.
Ekonomiska uttryck och ordföljder som i kalkylbladet splittras på flera rader märks lika på varje rad, så här:
| och |
O |
| var |
O |
| derför |
O |
| troligen |
O |
| en |
O |
| inkomst |
EKON |
| bringande |
EKON |
| affär |
EKON |
Du behöver minst 200 uppmärkta instanser, men ju fler du gör desto bättre kvalitet kan det bli på utfallet. Skulle det visa sig att ditt textavsnitt inte räcker till 200 uppmärkningar får du göra om proceduren såhär: Spara din redan gjorda märkning i kalkylbladsformat på skrivbordet, välj ett nytt lite längre avsnitt med samma början som det ursprungliga, ladda upp det och kopiera sedan av din märkning och klistra in i det nya kalkylbladet. Fyll på med nya uppmärkningar till (minst) 200.
Ta vara på din uppmärkningsfil, den är en värdefull resurs för bland annat upprepningsbarhet och validering och kan också komma till nytta i fortsatt arbete med ytterligare märkning av samma eller andra texter. När du är klar med uppmärkningen laddar du upp din fil till Swe-Clarins modellträningstjänst för kalkylblad som kör träningsprogrammet på den uppmärkta texten för att generera en ny modell.
Nu är det dags att låta den nya modellen automatiskt märka upp hela din källtext, som du laddar upp (i ordbehandlingsformat, max 80 MB) på Swe-Clarins entitetsuppmärkningstjänst för ordbehandlingsdokument.
Du får tillbaka den automatiskt uppmärkta texten i kalkylbladsformat. Andra kolumnen innehåller nu automatisk uppmärkning efter din egen annoteringsmodell och du kan vidare utforska texten genom att orientera mellan de märkta entiteterna.
I vissa fall var det ordnat så att en metallklocka slog om man träffade prick. Ofta bildades tävlingslag på två eller flera personer, varvid man köpte serier på fem skott vardera för 25 öre serien. Köpte man fem serier på en gång erhöll man en serie på köpet.
Vår uppmärkning av ekonomitermer i exempel-texten ger dock ett lite tunt utfall, förmodligen därför att de återgivna marknadsminnena sällan dröjer vid de köp och säljtransaktioner vi är ute efter. Kanske också för att vi borde gjort ett bättre förarbete med vår konceptuella avgränsning av temat. Modellen träffar, som du ser ovan, rätt på många köp och har även fångat in ett pris (25 öre), men frågan är om det ger meningsfull information utan koppling till vad det är som köps (här skott på en skjutbana). Det är ju dock inte modellens fel, utan uppmärkningens. Eventuellt kan det därför vara värt att göra bättre eller kompletterande uppmärkningar för att ge modellen bättre underlag.
3.5 Hur bra kan det bli?
Kvaliteten på utfallet beror i princip på antingen uppmärkningen eller källtexten. Vårt försök att märka upp ekonomi i frågelistan om marknadsnöjen lider lite av brister i det konceptuella förarbetet. Eftersom antalet uppmärkningar hålls extremt lågt, cirka 200 tokens, blir resultatet sämre även av detta skäl. Vår modell träffar till exempel bra på ören, skilling och styver, men missar bland annat kronor. Många ord som kan referera till ekonomi, till exempel rik och lån/låna, används även i många andra sammanhang och det har här bidragit till en viss brist på konsekvens i märkningen. Mer allmänt tal om pengar kan också vara svårt att avgränsa. Vad kan egentligen betecknas som en ekonomisk utsaga? En visa om hur bra det är i Amerika: renat brenvin man får för sex styver kannan? En man som varnar teaterpublik för att låta runka av sig pengar för sådant sabilens lort?
Vår uppmärkning hade förmodligen givit bättre utfall om vi på förhand listat relevanta ord eller åtminstone formulerat explicita kriterier för vårt intresseområde.
Möjligen är det också så att källtexten helt enkelt inte lämpar sig särskilt väl för att besvara våra frågor. Ekonomiskt sett är temat här billiga nöjen. De stora pengarna gick sannolikt till handel med djur och utsäde, som faller utanför denna frågelistas fokus. Alla sagesmän har inte lagt på minnet vad småsaker kostade för länge sedan: hur mycket dät kostade att få skjuta ett skott eller att få kasta en ring dät vet jag ej kan ej minnas om jag hörde dät. Ofta står det bara en slant.
Kanske var det också någon annan som betalade för nöjena: Vi var ett sällskap Flickor samt Pojkar de senare betalade intresavgift för Flickorna jag kan ej minnas hur mycket dät kostade. Här finns också många exempel på ekonomiska utbyten som inte är tydliga köp/sälj-affärer. Tittskåpsgubben till exempel som fick sova på en kärve ärthalm intill spisen, och visa sina sevärdheter för några ören pr person på gården i Boda – ska han betraktas som tiggare eller försäljare? Eller en grupp tyska hornblåsare som drog runt i Jämtland och objudna föredrogo sina stycken, varefter de pockade på duktigt med drickspengar?
Kanhända skulle man komma längre genom att tillämpa modellen – eller göra en ny uppmärkning – på en helt annan frågelista, Marknader och marknadsresor (Nm 45) från 1933.
4. Karta
Du vill få en överblick över geografiska mönster och hur de förändras över tid i dina källmaterial. Du behöver en metod för att extrahera ut geografisk information, till exempel ortsnamn eller x-/y-koordinater, ur din text för att kunna applicera dem på en kartbild.
5. Temamodellering (topic modeling)
Du vill kunna frilägga underliggande semantiska strukturer i ditt källmaterial. Du behöver applicera en metod som kan hjälpa dig att identifiera vissa teman för att till exempel kunna jämföra dem och navigera i andra liknande texter eller textpartier. Temamodellering (topic modeling) kan närmast beskrivas som en koncentrerad representation av vissa egenskaper i texten, till exempel i en värmekarta.
6. Ordklassuppmärkning
Du vill få en bild av händelser och aktiviteter i dina texter, och det kan du få genom att filtrera fram verb som ordklass. Du behöver annotera källmaterialen med en ordklasstaggare, det vanliga är använda en befintlig modell tränad på SUC. En ordklassuppmärkning lägger också grunden för ytterligare extrahering av information och kompletterande annotering, till exempel universal dependencies.
7. Dependensuppmärkning
Du vill få en klarare bild av aktörerna i texten, hur de förhåller sig till varandra och var och när saker äger rum. Du behöver applicera en uppmärkningsmodell för satsanalys på ditt material. Sådana är ofta baserade på Talbanken men det finns många olika parsrar och vilken du väljer beror bland annat på vilka andra verktyg du vill använda. Även dependensuppmärkning lägger grund för ytterligare extrahering av information och kompletterande annotering.
8. Nätverksanalys
Du vill titta på hur namngivna entiteter, typiskt sett personer och organisationer, i dina källor förhåller sig till varandra. Vem står i beroendeställning till vem? Närmar de sig varandra eller glider isär över tid? Du behöver en metod för att extrahera ut namngivna entiteter ur din text och kartlägga deras inbördes relationer, till exempel i ett sociogram.
9. Attitydanalys (sentiment analysis)
Du vill titta på hur olika företeelser kopplas till attityder i dina källmaterial. Finns till exempel platser, personer eller företeelser som framställs som positivt eller negativt laddade? Du behöver tillräckliga mängder material att annotera med värden som i den givna kontexten indikerar attityd på en skala från mycket negativ till mycket positiv. Det kan handla om explicita åsikter och omdömen men också mer underliggande etos, patos och sentiment.
FÖRFATTARE
Leif-Jöran Olsson
Språkbanken Text
Johanna Berg
Digisam på Riksarkivet
ORDLISTA
Annotering information som tillförs en text, manuellt av en människa eller automatiskt av ett verktyg. Annotering kan göras på olika nivåer (ord, mening, stycke)
Entitet benämnd enhet
Flerordsuttryck ord som ofta uppträder ihop och som språkligt beter sig som en enhet, till exempel ad hoc
KWiC (keyword in context) visuell uppställning av ett ord eller uttryck i sitt sammanhang, ofta benämnt konkordans
Korpus samling texter som sammanställts i ett visst syfte
Lemgram ordklassbaserat samlingsbegrepp för ett ords eller flerordsuttrycks samtliga böjningsformer
Lexicographer's Mutual Information-värde mått på i vilken utsträckning ord uppträder nära varandra, mer frekvent än vad som skulle kunna förklaras med slumpmässigt sammanträffande
Parsning, syntaktisk analys som identifierar beståndsdelarna i en sats och deras inbördes relationer
Precision frekvens relevanta entiteter i en sökning/filtrering
Segmentering sätt att dela upp en text i ord eller ordliknande enheter som är användbara i det fortsatta arbetsflödet
Sökaktiviteter filtrering, gruppering, navigering
Token ord, flerordsuttryck, interpunktion med mera enligt en specifik segmentering
Karp Språkbanken Texts lexikala plattform Karp
Korp Språkbanken Texts korpussökningsverktyg Korp
Sparv Språkbanken Texts annoteringskedja Sparv