
Vilket är förhållandet mellan text och språk? Med språkteknologiska resurser av olika slag kan vi fånga diverse språkliga egenskaper hos en text framför allt utifrån ord och meningar i termer av frekvenser och automatiska analyser av ordklasser, ordförråd och grammatiska relationer.
I projektet STePS vill vi utveckla ett system som ger textforskare av olika slag möjlighet att använda och anpassa olika automatgenererade textmått för egna behov. STePS utnyttjar resultat från projektet Diginclude men utökar och anpassar dem för andra målgrupper, specifikt textforskare. Idag finns ett mycket stort antal mått som grundar sig på olika resurser så som SweVoc-lexikonen(1), ordklasstaggare och dependensparsning. Det går att presentera måtten på olika sätt, t.ex. i tabellform eller i radardiagram. I diagrammen nedan jämförs utdrag från verk av två olika författare men skrivna vid ungefär samma tidpunkt.
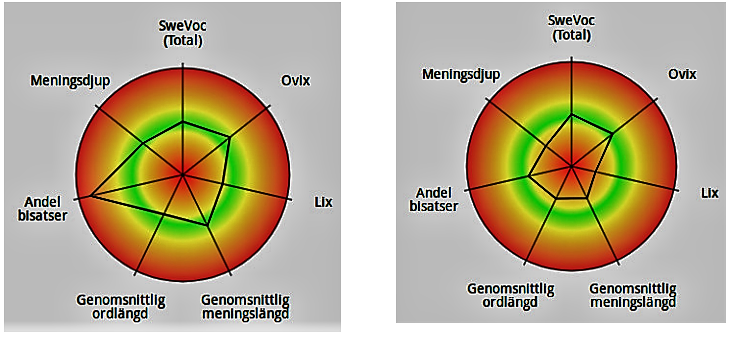
I detta fall kan skillnaden till stor del förklaras genom förhållandet mellan dialog och berättande i de två texterna, vilket antyder att möjligheten att skilja och klassificera olika slags text vore värdefull att ha. Det finns i nuläget heller inga mått som direkt tar sikte på meningsövergripande egenskaper, t.ex. förekomsten av olika strategier för textbindning. Till en viss del kan sådan egenskaper fångas av enklare mått så som t.ex. förhållandet mellan samordnande och underordnande konjunktioner eller förhållandet mellan pronomen och nomen, men kohesionsmått som använder samförekomster av namn eller nomen är något av det vi vill tillföra(2).
Det pågående arbetet ägnas framför allt åt att definiera nästa version av systemet, vilket vi vill göra i samarbete med textforskare.
LARS AHRENBERG
__________________
(1) Katarina Mühlenbock och Sofie Johansson Kokkinakis, 2012. SweVoc - A Swedish vocabulary resource for CALL. Proceedings of the SLTC 2012 workshop on NLP for CALL, Lund, 25th October, 2012.
(2) Danielle S. McNamara, Max M. Louwerse, Philip M. McCarthy & Arthur C. Graesser, 2010. Coh-Metrix: Capturing Linguistic Features of Cohesion. Discourse Processes, 47(4)