
What is the relationship between text and language? Language technology tools allow us to capture various linguistic characteristics of a text, primarily based on words and sentences in terms of frequencies and automatic analyses of vocabulary, parts-of-speech, and grammatical relationships.
The aim of the STePS project is to develop a system that would allow text researchers to use and adapt different automated text metrics for their own needs. STePS uses results from the Diginclude project but extends and adjusts them to other target groups, specifically text researchers. Diginclude metrics are based on various resources, such as the SweVoc lexicon(1), part-of-speech tagging and dependency parsing. The metrics can be presented in different ways, eg. in tabular form or in radar diagrams. The diagrams below compare extracts from works by two different authors written at about the same time.
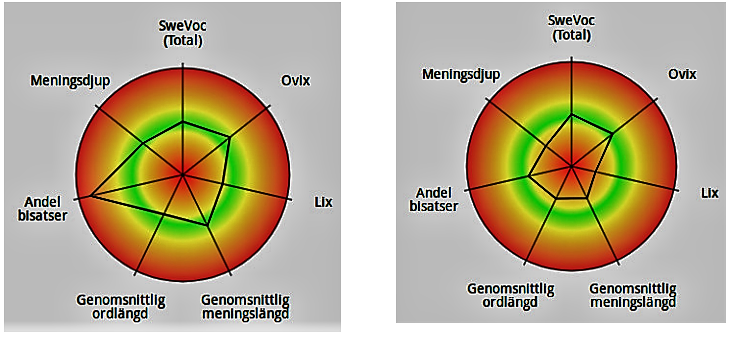
In this case, the difference can largely be explained by the relationship between dialogue and narrative in the two texts, suggesting that the ability to differentiate and classify different types of text would be valuable. There are currently no metrics that directly target meaningful features such as the existence of different text binding strategies. To some extent, such features can be captured by simpler means such as, for example, the proportion of coordinating conjunctions to subjunctions or the proportion of personal pronouns to nouns, but cohesion metrics that use co-occurrences of names or nouns across sentences are some of the things we want to include.
Current work is mainly targetted at defining the next version of the system, something we want to do in collaboration with text researchers(2).
Lars Ahrenberg
__________________
(1) Katarina Mühlenbock och Sofie Johansson Kokkinakis, 2012. SweVoc - A Swedish vocabulary resource for CALL. Proceedings of the SLTC 2012 workshop on NLP for CALL, Lund, 25th October, 2012.
(2) Danielle S. McNamara, Max M. Louwerse, Philip M. McCarthy & Arthur C. Graesser, 2010. Coh-Metrix: Capturing Linguistic Features of Cohesion. Discourse Processes, 47(4)