
The Department of Linguistics at Stockholm University, in a collaboration with Uppsala University, has integrated several previous language-technology tools into a combined annotation pipeline for Swedish text. The sequence tagger efselab (Stockholm) handles annotation of parts of speech, name categories and morphology, to which is added syntactic dependency analysis using the MaltParser tool from Uppsala. In addition to the tools themselves, we have harmonized a number of Swedish corpora and lexical resources: the SUC corpus (produced by Stockholm University and Umeå University), the SIC corpus (Stockholm), the Swedish Universal Dependencies treebank (Uppsala), and the morphological dictionary SALDO (Gothenburg). These resources have been developed for several decades at different sites, usually without coordination or standardization. Even though each individual resource is of high quality, the lack of compatibility has led to the fact that many language-technology users out of convenience have chosen to use only a subset of the available resources, affecting results negatively.
In addition to the integration itself, we have also adapted the tools to the Universal Dependencies standard, thereby making the annotation compatible with treebanks from over 50 different languages. These are used extensively in both language technology, where they constitute an important component for the purpose of developing language-independent methods, and in basic linguistic research.
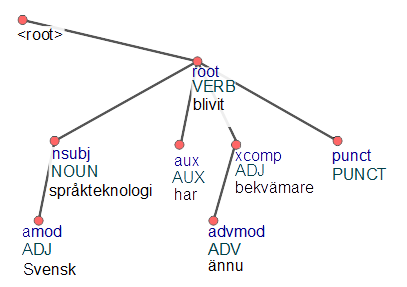
Tools, source and model files are available at https://github.com/robertostling/efselab . Large parts of the infrastructure are also used by the web-based SWEGRAM tool (Uppsala) at http://stp.lingfil.uu.se/swegram/