The language technology group at Uppsala university is developing resources and tools for automatic analysis and processing of language data. We want to enable large-scale quantitative text analysis for researchers in the field of humanities and social sciences who do not neccessarily have the programming skills required to directly make use of our tools, which have originally been developed for automatic natural language processing.
In order to make our tools more accessible to users from the above mentioned fields, we have developed SWEGRAM, a web-based open platform onto which one or more Swedish texts can be uploaded and then analysed on different levels. SWEGRAM provides the possibility to perform tokenization (segmenting texts into sentences and words), part-of-speech tagging
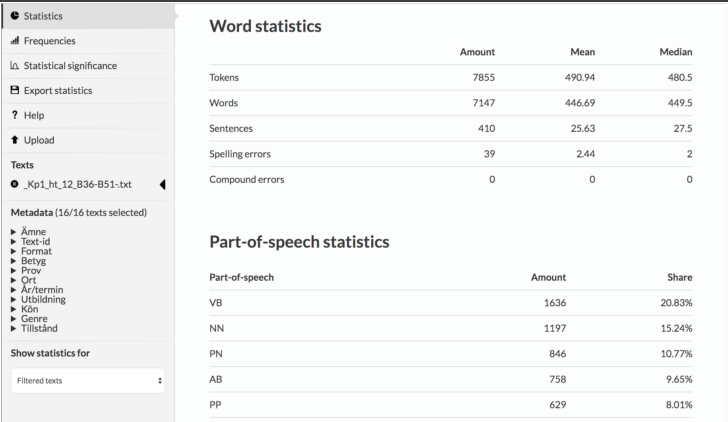
(assigning a grammatical word class to each word), lemmatization (identification of the base form of each word) and sentence-level syntactic analysis using dependency relations. Moreover, this tool also produces language statistics based on the annotation categories. For example, it provides statistics about word and sentence counts, number of words per word class, different readability measures, typing errors, and frequency lists based on words, base forms or word classes. SWEGRAM allows users to create their own annotated text ollections (so-called corpora) and to compare texts on different levels of language analysis.
An example analysis is given below, taken from a corpus consisting of student writings from the national exam in Swedish for different courses, which has been built using SWEGRAM. SWEGRAM has been developed att Uppsala university at the Department of Linguistics and Philology in collaboration with the Department of Scandinavian Languages. SWEGRAM has been partially funded by the SWE-CLARIN project.